This series of blog posts, similar to previous posts about Azure Service Bus, is intended for those who already have some MSMQ experience and would like to know more about RabbitMQ. It’s based on my own experiences when I learned about RabbitMQ, what was familiar and what not, and what looked familiar but surprised me in one way or the other. Since I assume you worked with MSMQ before, I won’t explain common queuing concepts. Idea is to get you up to speed quickly without wasting time on things you already know.
Introduction
RabbitMQ is an open source message broker, which can be installed on different operating systems, not only on Windows like MSMQ. It’s written in Erlang, and thus require that you install Erlang runtime first. That’s all covered in installation guide:
https://www.rabbitmq.com/download.html
RabbitMQ supports plugins, and a lot of functionality is implemented that way. For instance, if you want to do any kind of management (including connecting from QueueExplorer), you have to enable Management plugin:
https://www.rabbitmq.com/management.html
Once enabled, it offers browser-based management interface. That plugin is already included in RabbitMQ installation, just disabled by default.
Exchanges – a post office for RabbitMQ
While RabbitMQ has queues which are similar to MSMQ, they have one striking difference – you cannot send messages directly to them! Instead, you always send a message to an exchange, and then exchange passes it to destination queue (or queues).

Exchange doesn’t store messages at all, it just passes them immediately to one or more configured destinations. Key thing to notice here is “one or more”. It’s possible to configure exchange to send a single message to multiple destination queues! During that, each destination queue gets its own copy of message. With this, RabbitMQ supports “publish/subscribe” pattern out of the box meaning each subscriber receives and consumes same messages, but each on its own pace.
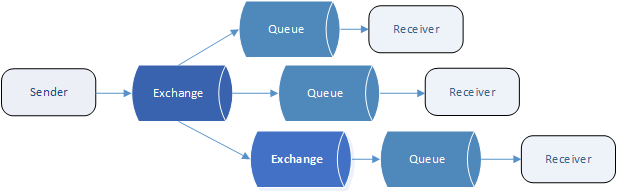
Apart from queues, destination can be another exchange, so message can go through multiple intermediate steps (i.e. exchanges) until it ends up in actual queue. Also, you can choose which messages are passed to which destinations, depending on message’s content – e.g. exchange could accept two different messages, and pass first one to queue1, and second one to queue2.
This configurable connection between exchanges and queues is called binding. Since bindings in RabbitMQ are configurable at run time, you can adapt how messages flow through your system without changing sending or receiving applications.
Virtual hosts
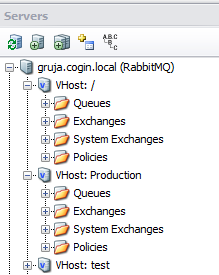
RabbitMQ can run multiple “Virtual hosts” on the same server. Virtual host is like a separate standalone instance – it has its own set of queues, exchanges, bindings, users, permissions, etc. That’s an easy way to separate and isolate different applications, without having to run multiple brokers. For instance application with permissions on one virtual host can’t send or receive messages on another one, you can have queues with same names on different virtual hosts, etc. But virtual hosts are not physically isolated – they can affect performance of each other.
RabbitMQ messages
On the first glance RabbitMQ messages are similar to MSMQ – there’s Message Id, Body, as well as a bunch of other parameters. However, there are some major differences – by default RabbitMQ doesn’t fill most of these fields. For instance, Message Id is just a field where you can put anything – and RabbitMQ won’t fill it by itself if it’s empty! Because of that there are no guarantees of unique IDs, there could be even completely identical messages and system doesn’t perform any duplicate detection at all. RabbitMQ doesn’t even autofill “Send time” field.
Also, there’s no Label like in MSMQ, but we can argue that “Message Id” is a substitute since it’s a field filled by user. There’s also no limit for body size, which could be convenient in some cases.
What RabbitMQ does have and MSMQ doesn’t are message headers. Each message has a key-value store where you can put your custom data. That data can later be used for exchange routing, so that different messages go to different destinations. Or you can just access that data directly from your receiving app instead of parsing it from body, like you would have to do in MSMQ.
Machine to machine communication
One of MSMQ premises is that MSMQ service must be installed on all machines which use it. Even if your application is sending message to a remote machine, it only ever communicates with local MSMQ. That local communication on same machine is typically very reliable. After that point, it’s MSMQ’s responsibility to connect to remote machine and deliver messages over network, possibly retry sending if there are communication issues or destination is down, etc. Pending messages are stored in MSMQ outgoing queues until they are delivered (or expire). Therefore, as soon as message is received locally, your app is free to do whatever it wants, can be shut down, restarted, etc.
RabbitMQ doesn’t generally work that way – you don’t have to run broker on machine where messages are sent or consumed. Therefore this communication between your application and RabbitMQ server could be a weak point, if going over network. There are no separate processes or local queues to keep outgoing messages in case of problems. It’s up to your application to handle network issues, either to stop creating and sending messages (effectively to stop working from user point of view), or to keep pending messages in some custom local storage.
Of course, nothing stops you from installing RabbitMQ instances on machines where applications are run. However, if you want local RabbitMQ to pass messages to remote one it’s not as simple as just putting a different machine for destination address like it’s in MSMQ.
We’ll talk more about distributed aspects in one of following posts, but next post will dive more into exchanges.
Links to all 6 parts of this series.