When working with MSMQ, we usually don’t think about “distributed brokers” as a separate topic. It’s core MSMQ functionality. From user’s point of view, you only change destination address (i.e. format or path), and message magically goes to remote MSMQ server. Behind the scene, it’s supported by outgoing queues where messages are temporarily stored until they’re delivered, they’re retried if destination or network is down, etc. In fact, MSMQ doesn’t even offer us to talk directly with some remote server – all communication always goes through local service.
With RabbitMQ it’s not as simple. It’s quite usual that you’ll set up just one broker and use it remotely from multiple hosts. However, it does have some kind of support for connecting multiple brokers – Federation and Showel. They are both implemented as RabbitMQ plugins, included in installation but not enabled by default. We’ll also talk about clustering.
Federation
Federation is a way to connect queues and exchanges, which can reside on different brokers. It’s a one-way type of connection – we define an “upstream”, and that upstream defines where messages come from. Federation is set up on “destination” broker, nothing is configured on the source.
Federated exchanges
If two exchanges are federated, copies of messages are forwarded from source to destination. It’s very similar to binding, except that destination exchange can be on a different broker. Behind the scene, this is supported by “upstream queue” on source broker – it’s similar concept to MSMQ outgoing queue, since it keeps messages which are not delivered yet. You’ll recognize it by “federation:” prefix, and its name tells us for which destination it is.
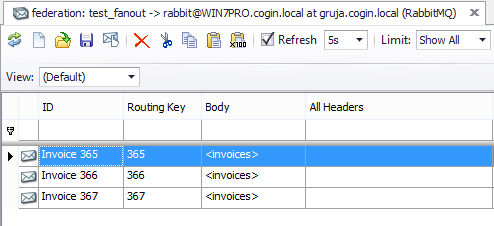
We can use QueueExplorer to see or modify messages which are waiting for delivery. RabbitMQ automatically creates “federated” exchange, also on source broker:
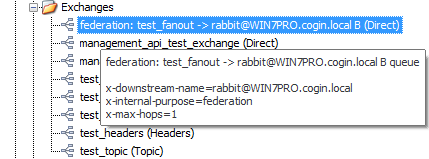
Federated exchanges are fairly complex to set up. First, you have to define upstream, and then you have to create a policy which will apply federation. You can see more details about federated exchanges here:
https://www.rabbitmq.com/federation.html
https://www.rabbitmq.com/federated-exchanges.html
Federated queues
Federated queues are a bit different – destination queue acts as a consumer for source queue. When a message is consumed on a destination machine, it gets removed from source queue and no other consumer will see it. Therefore each message is processed only once, either by a consumer on a source machine, or by some of federated destination queues (there can be more that one), whichever receives it first. That is different from Federated exchanges, where messages are duplicated and all receivers receive all messages.
Effectively, all federated queues act as a single logical queue, with multiple receivers on multiple machines. So federated queues can be used for load balancing.
http://www.rabbitmq.com/federated-queues.html
Shovel
Shovel is a plugin which moves messages from one place to another. It’s like a client which we could write (but don’t have to), which receives messages from a queue and sends them to an exchange, including handling failures in that process. Queue and exchange can be on same or different virtual host, or on another broker. It can be set up on independent node, and configured however we like. Problem with shovel was that we had to restart a broker where it runs in order to reconfigure it, but dynamic shovels removed that limitation.
https://www.rabbitmq.com/shovel.html
Clustering
RabbitMQ clustering is different from MSMQ. They both consist of multiple nodes which show up as single logical broker. Let’s recall first how clustering works on MSMQ. Only one node is kept active, other will take over only if the first one fails, aka active/passive configuration. There are no performance gains from additional machine(s), but there are also no problems with consistency between nodes, if one fails. Queues and messages are kept on shared storage.
On RabbitMQ cluster is geared toward increasing scalability, not high availability. All nodes in a cluster work all the time, and load is distributed, which improves performance. Definitions (e.g. queue/exchange names/parameters, users, policies, etc) are distributed on all nodes. However, by default, queue messages reside on just one of the nodes. Such queue is not fault tolerant. If node fails, queues from that node won’t be available anymore.
In order to get high availability, RabbitMQ has a feature called queue mirroring, which can be turned on after cluster is created. With mirroring turned on, messages will be synced to other nodes. However, they’ll still be consumed only from their primary location (i.e. master queue) and other nodes will just maintain their own copy of queue. When node fails, one of mirrored nodes takes over.
Problem is if there are communication issues between nodes. They may end up thinking that other node(s) are down, and continue separately. If messages are not produced/consumed in the exactly same way on disconnected nodes, they’ll end up with conflicting data. That state is known as a network partition. In these cases RabbitMQ cluster requires manual intervention after failures, although there are few auto modes where cluster would try to fix problems itself.
https://www.rabbitmq.com/clustering.html
In the last part of this series we’ll talk about RabbitMQ programming basics.
Links to all 6 parts of this series.
One thought to “Distributed brokers – RabbitMQ for MSMQ users, part 5”
Comments are closed.