Introduction to RabbitMQ
RabbitMQ is a technology for asynchronous messaging. Whenever there's need for two or more applications (services, processes...) to send messages to each other without having to immediately know the results, a messaging solution like RabbitMQ is much better than tightly coupled synchronous (RPC, REST...) calls.
Applications using RabbitMQ communicate by sending Messages. Messages are kept in a queue. Producers send them to the queue, and Consumers receive them from the queue. By putting a queue between these two parties, we're decoupling Producers and Consumers, and at the end get much more resilient system.
Main benefits of RabbitMQ compared to synchronous calls
- Producers and Consumers run independently - one of services can be down, and the other one doesn't have to fail as well. They are not directly connected.
- Buffering - if producer is faster than consumer, it doesn't have to wait for consumer to complete, or overrun downstream system which then brings everything down. If we have a burst of messages they will be stored in a queue to be processed later.
- Distributing load - Producers and Consumers don't have to be in one-to-one relationship. You can have multiple producers and multiple consumers, which can share messages in multiple different ways. For instance you can add more consumers to the mix to get more throughput.
- Separate Consumers for separate functionalities - aka publish/subscribe. Your Producer can create a message when important event happens and you can have multiple different consumers, each doing its own thing with a message. In a way "subscribing" to event. For instance if we create a message when order is received, we can have one consumer for invoicing, another one to communicate with payment processor, another one to initiate shipping, etc.
If you need another thing happening for that event you just set up a new consumer and configure RabbitMQ to send to it as well, without changing Producer or any of existing consumers.
In general case, applications working with RabbitMQ are not aware of how these connections are set up, that's configured in RabbitMQ. And therefore can be reconfigured as needed, without touching actual Producers and Consumers. - Serialization of jobs - when multiple update requests hit the database at the same time, we could end up with transaction locking problems. Queues allow us to perform db jobs one by one and not in parallel. Or do any kind of processing which has to be serialized.
- Easier handling of problematic scenarios - RabbitMQ allows us to retry messages, move bad message to a separate queue if we can't process it (so called deadletter queue), can be set to automatically expire old messages, etc.
Getting started
RabbitMQ is an open source message broker, which can be installed on different operating systems. It's written in Erlang, and thus require that you install Erlang runtime first. That's all covered in the official installation guide.
RabbitMQ supports plugins, and a lot of functionality is implemented that way. For instance, if you want to do any kind of management (including connecting from QueueExplorer), you have to enable Management plugin. Once enabled, it offers browser-based management interface. That plugin is already included in RabbitMQ installation, just not enabled by default.
RabbitMQ queues
Queues are first in - first out structures for holding messages. Queues hold messages which are created by Producers, but not yet received by Consumers. Once Consumer received a message, it gets removed from a queue.
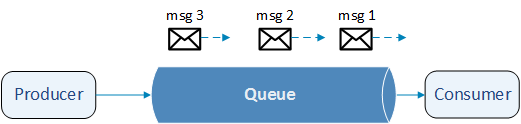
Exchanges - a post office for RabbitMQ
You cannot send messages directly to a queue. Instead, you always send a message to an exchange, and then exchange passes it to a destination queue (or queues). This allows Producers and Consumers to be separated from actual messaging topology (routing of messages), and will continue to work even if you reconfigure RabbitMQ.

Exchange doesn't store messages at all, it just passes them immediately to one or more configured destinations. Key thing to notice here is "one or more". It's possible to configure exchange to send a single message to multiple destination queues! During that, each destination queue gets its own copy of a message. With this, RabbitMQ supports "publish/subscribe" pattern out of the box meaning each subscriber receives and consumes same messages, but each on its own pace.
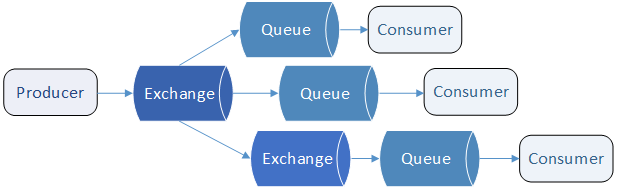
Apart from queues, destination can be another exchange, so message can go through multiple intermediate steps (i.e. exchanges) until it ends up in actual queue. Also, you can choose which messages are passed to which destinations, depending on message's content - e.g. exchange could accept two different messages, and pass first one to queue1, and second one to queue2.
This configurable connection between exchanges and queues is called binding. Since bindings in RabbitMQ are configurable at run time, you can adapt how messages flow through your system without changing sending or receiving applications.
Virtual hosts
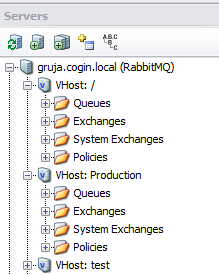
RabbitMQ can run multiple "Virtual hosts" on the same server. Virtual host is like a separate standalone instance - it has its own set of queues, exchanges, bindings, users, permissions, etc. That's an easy way to separate and isolate different applications, without having to run multiple brokers. For instance application with permissions on one virtual host can't send or receive messages on another one, you can have queues with same names on different virtual hosts, etc. But virtual hosts are not physically isolated - they can affect performance of each other.
QueueExplorer can work open just a single virtual host, or all of them from the RabbitMQ broker.
RabbitMQ messages
RabbitMQ messages don't just carry your data (also known as "message body"). They contain multiple other parameters, message Id, routing key, timestamp, correlation Id, content type and encoding, etc. However, RabbitMQ doesn't fill most of these fields itself. For instance, Message Id is just a field where you can put anything and can be left empty! Because of that there are no guarantees of unique IDs, there could be even completely identical messages and system doesn't perform any duplicate detection at all. RabbitMQ doesn't even autofill "Send time" field.
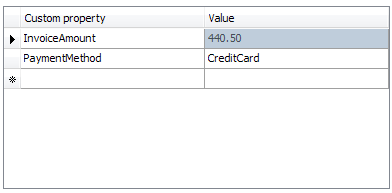
It can also hold a number of your own custom properties - essentially there's a key-value store in each message. That data can later be used for routing purposes, so that different messages automatically go to different destinations. Or you can just access that data directly from your receiving app instead of parsing it from body.
QueueExplorer: Explorer-like management for RabbitMQ

We developed a software which greatly helps you with RabbitMQ. It helps you to understand and manage your system, figure out what went wrong, and fix it. There is a free trial as well.